They don't look at it letter by letter but in tokens, which are automatically generated separately based on occurrence. So while 'z' could be it's own token, 'ne' or even 'the' could be treated as a single token vector. of course, 'e' would still be a separate token when it occurs in isolation. You could even have 'le' and 'let' as separate tokens, afaik. And each token is just a vector of numbers, like 300 or 1000 numbers that represent that token in a vector space. So 'de' and 'e' could be completely different and dissimilar vectors.
so 'delaware' could look to an llm more like de-la-w-are or similar.
of course you could train it to figure out letter counts based on those tokens with a lot of training data, though that could lower performance on other tasks and counting letters just isn't that important, i guess, compared to other stuff
{kind=link}
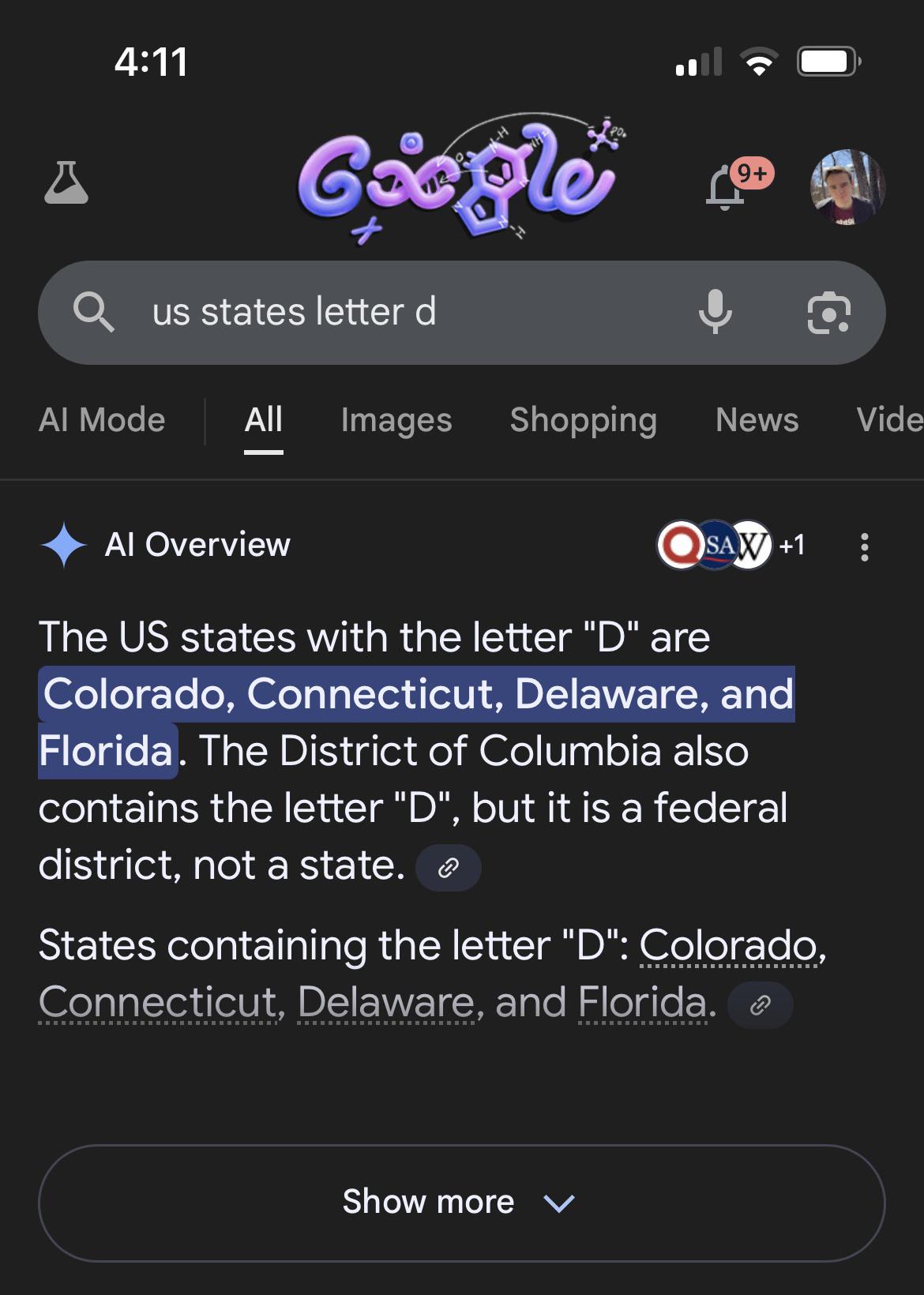
Well, for anyone who knows a bit about how LLMs work, it’s pretty obvious why LLMs struggle with identifying the letters in the words
Well go on..
They don't look at it letter by letter but in tokens, which are automatically generated separately based on occurrence. So while 'z' could be it's own token, 'ne' or even 'the' could be treated as a single token vector. of course, 'e' would still be a separate token when it occurs in isolation. You could even have 'le' and 'let' as separate tokens, afaik. And each token is just a vector of numbers, like 300 or 1000 numbers that represent that token in a vector space. So 'de' and 'e' could be completely different and dissimilar vectors.
so 'delaware' could look to an llm more like de-la-w-are or similar.
of course you could train it to figure out letter counts based on those tokens with a lot of training data, though that could lower performance on other tasks and counting letters just isn't that important, i guess, compared to other stuff
Good read. Thank you