No, LLMs produce the most statistically likely (in their training data) token to follow a certain list of tokens (there's nothing remotely resembling reasoning going on in there, it's pure hard statistics, with some error and randomness thrown in), and there are probably a lot more lists where Colorado is followed by Connecticut than ones where it's followed by Delaware, so they're obviously going to be more likely to produce the former.
Moreover, there aren't going to be many texts listing the spelling of states (maybe transcripts of spelling bees?), so that information is unlikely to be in their training data, and they can't extrapolate because it's not really something they do and because they use words or parts of words as tokens, not letters, so they literally have no way of listing the letters of a word if said list is not in their training data (and, again, that's not something we tend to write, and if we did we wouldn't include d in Connecticut even if we were reading a misprint). Same with counting how many letters a word has, and stuff like that.
{kind=link}
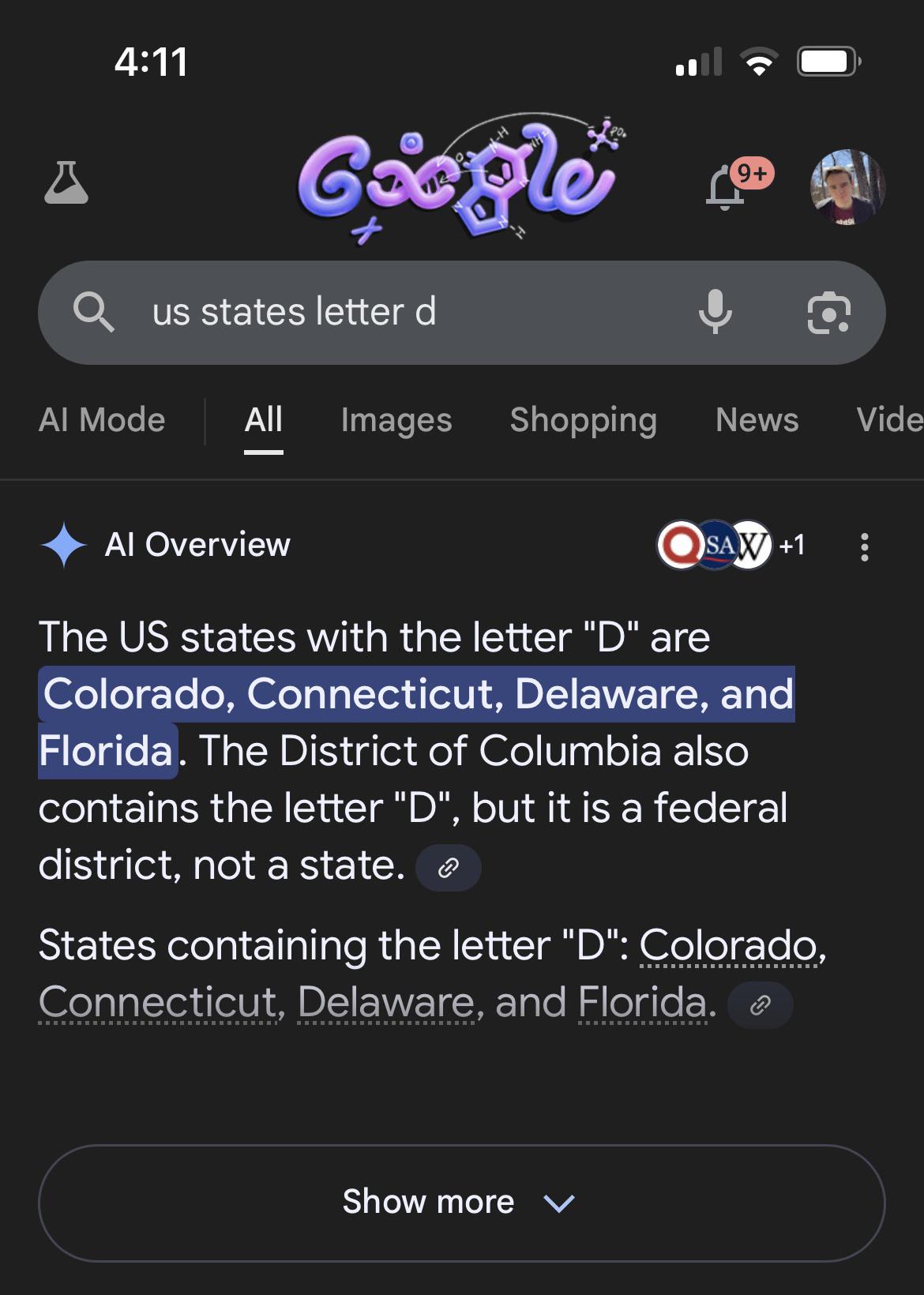
No, LLMs produce the most statistically likely (in their training data) token to follow a certain list of tokens (there's nothing remotely resembling reasoning going on in there, it's pure hard statistics, with some error and randomness thrown in), and there are probably a lot more lists where Colorado is followed by Connecticut than ones where it's followed by Delaware, so they're obviously going to be more likely to produce the former.
Moreover, there aren't going to be many texts listing the spelling of states (maybe transcripts of spelling bees?), so that information is unlikely to be in their training data, and they can't extrapolate because it's not really something they do and because they use words or parts of words as tokens, not letters, so they literally have no way of listing the letters of a word if said list is not in their training data (and, again, that's not something we tend to write, and if we did we wouldn't include d in Connecticut even if we were reading a misprint). Same with counting how many letters a word has, and stuff like that.